python을 활용하여 json파일을 읽어들이고, 필요한 정보만 변수에 저장하여 json파일을 새로 작성하는 방법에 대해 정리한 게시글이며
해당 작업을 진행하면서 확인하게 된 몇개의 예외상황에 대한 해결방법을 정리해보았다.
목차는 아래와 같으며, 정상 수행 코드를 먼저 첨부한 후 발생했던 예외 상황에 대하여 설명하는 방식으로 진행된다.
1. 파일 읽기
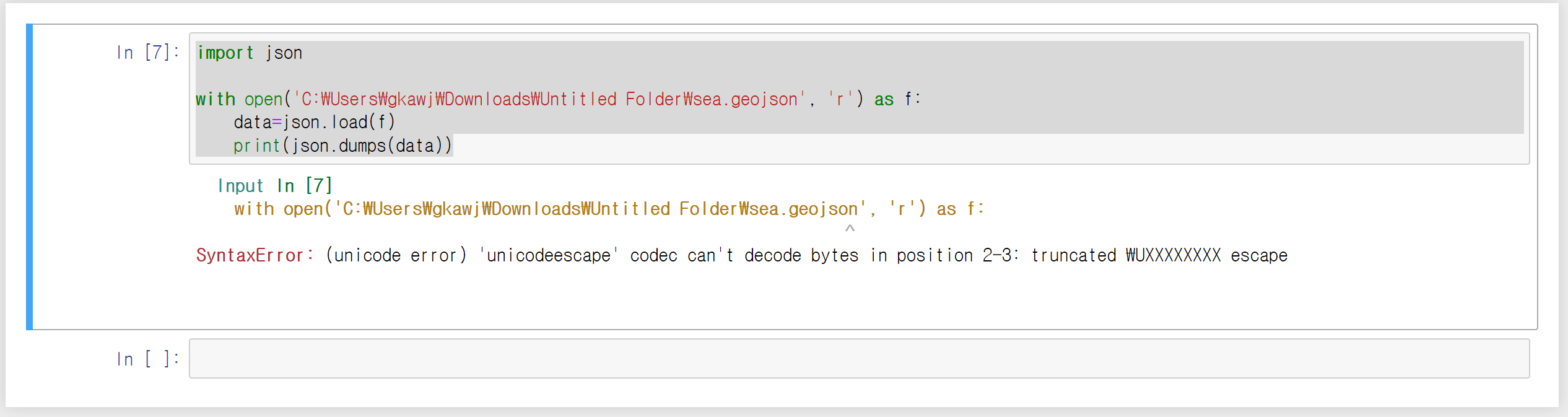
1) SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escape
2) UnicodeDecodeError: 'cp949' codec can't decode byte 0xec in position 196: illegal multibyte sequence
3) 한글깨짐 해결
2. 필요한 값 변수에 저장하기
1) TypeError: list indices must be integers or slices, not str
3. 파일 쓰기
1) 인코딩 문제(한글깨짐)
총 44개의 해구에 대한 좌표가 모두 들어있는 geojson파일을, 양식에 맞춰 한개의 해구별마다 하나의 파일로 분리하여 저장하는 작업을 다룰 예정이다.
사용한 파일을 첨부하였다.
1. 파일 읽기
아래에 첨부된 코드를 통해 총 44개의 해구 정보가 기입된 5천줄 이상의 geojson파일이 정상적으로 읽어진 모습을 확인할 수 있다.
import json
with open('C:\\Users\\gkawj\\Downloads\\Untitled Folder\\sea.geojson', 'r',encoding="UTF-8") as f:
data=json.load(f)
print(json.dumps(data, indent="\t", ensure_ascii=False))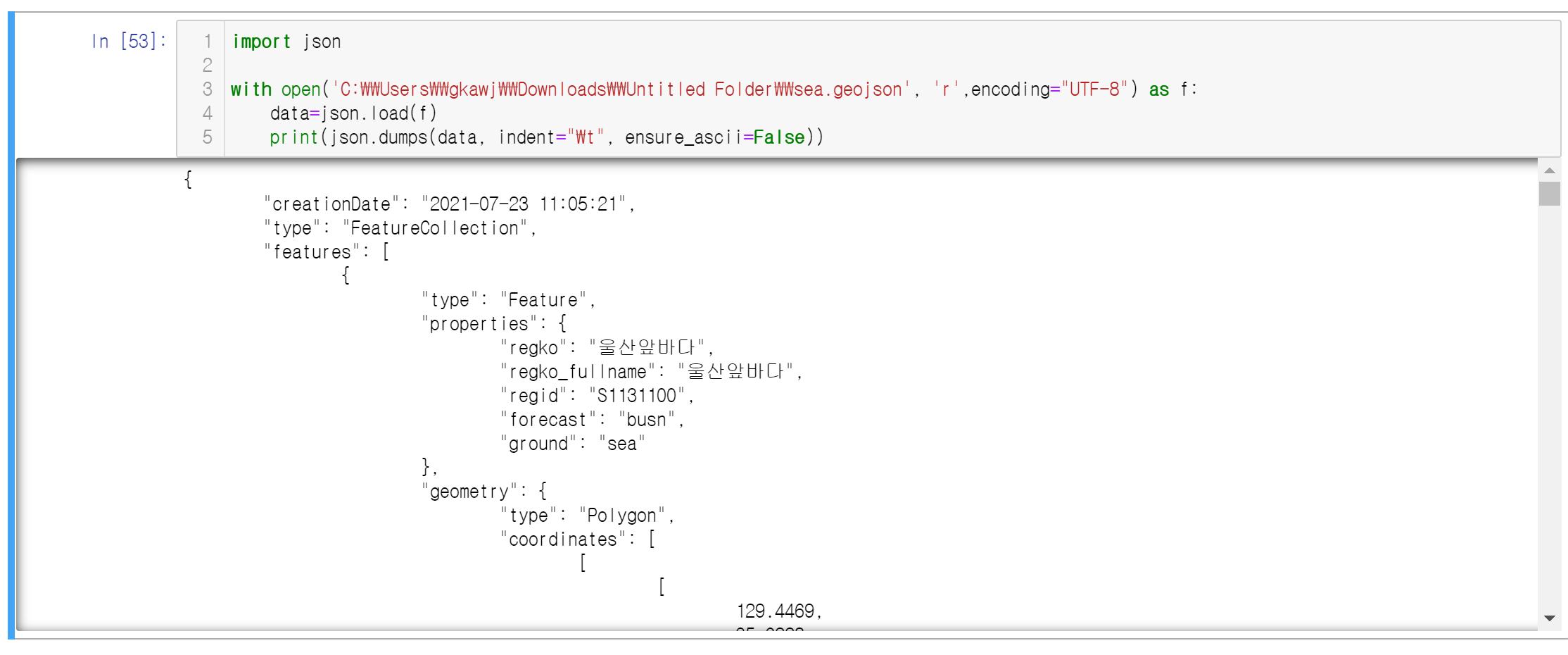
1) SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escape

경로 표시에 사용된 \(원화표시)가 유니코드로 읽혀서 발생하는 예외라고 한다.
이 경우 원화표시를 /로 변경하거나, \\로 대체하여 사용하면 해결된다.
#기존코드
C:\Users\gkawj\Downloads\Untitled Folder\sea.geojson
# 추천방법 1
C:\\Users\\gkawj\\Downloads\\Untitled Folder\\sea.geojson
# 추천방법 2
C:/Users/gkawj/Downloads/Untitled Folder/sea.geojson
python error 해결법: SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXX
파이썬에서 파일을 불러오거나 할때 아래와 같은 에러가 나타날 때가 있다. path = 'C:\Users\Downloads\NanumBarunGothic.ttf' SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in posit..
wotres.tistory.com
2) UnicodeDecodeError: 'cp949' codec can't decode byte 0xec in position 4: illegal multibyte sequence
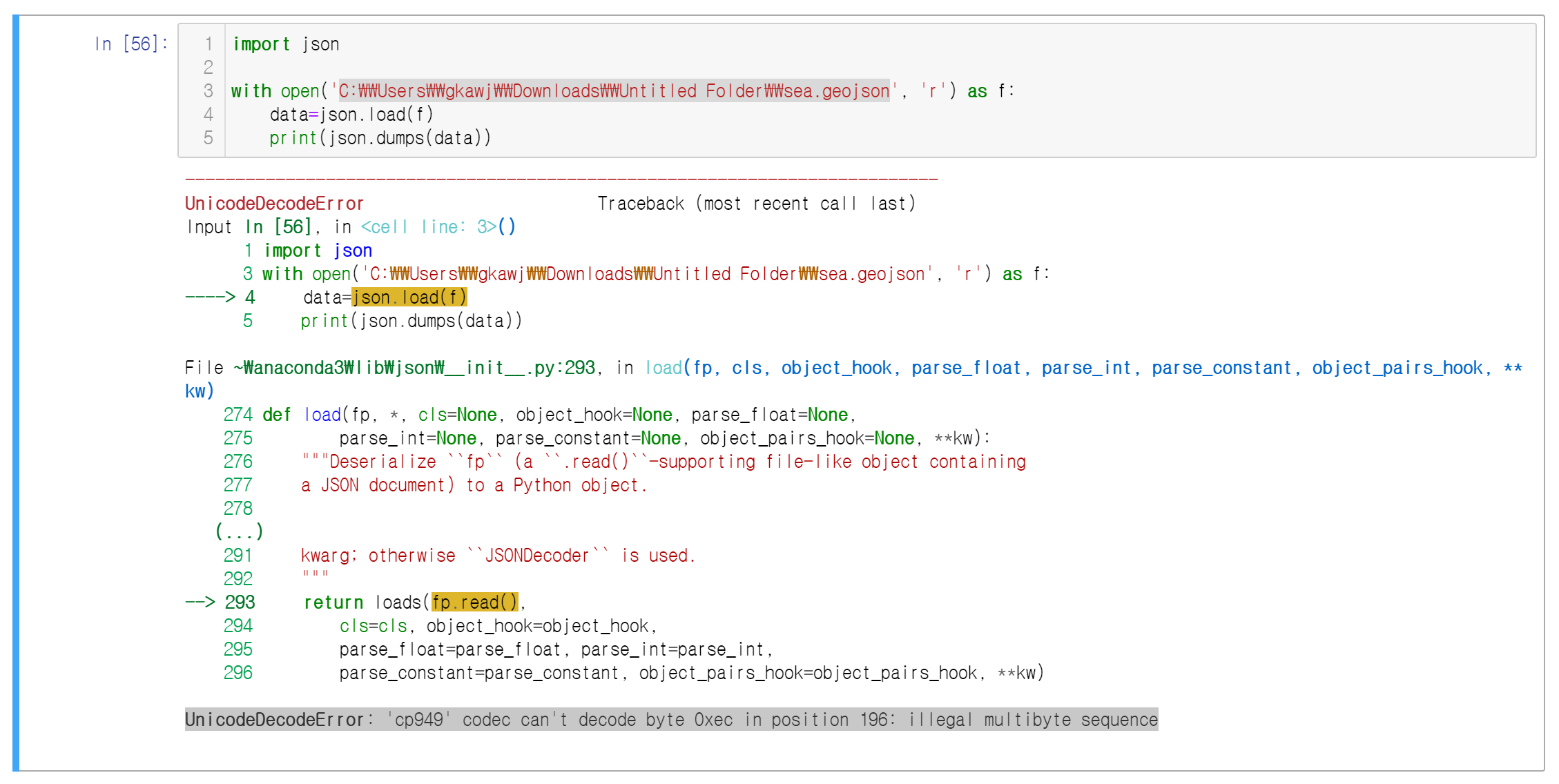
문자 인코딩 방식이 달라 디코딩 하는데 예외가 발생한다는 의미라고 한다. 이 경우 UTF-8로 설정한다는 내용을 별도로 명시해주면 해결된다.
# 수정 전
with open('C:\\Users\\gkawj\\Downloads\\Untitled Folder\\sea.geojson', 'r') as f:
# 수정 후
with open('C:\\Users\\gkawj\\Downloads\\Untitled Folder\\sea.geojson', 'r', encoding="UTF-8") as f:
https://gwpaeng.tistory.com/313
[Error] UnicodeDecodeError: 'cp949' codec can't decode byte 0xec in position 4: illegal multibyte sequence
open error txt file을 open 하고 .readlines()할때 문제가 발생한 것 같습니다. 그래서 찾아보니 UnicodeDecodeError : 'cp949'코덱은 위치 4에서 0xec 바이트를 디코딩 할 수 없습니다. 잘못된 멀티 바이트 시퀀..
gwpaeng.tistory.com
3) 한글깨짐
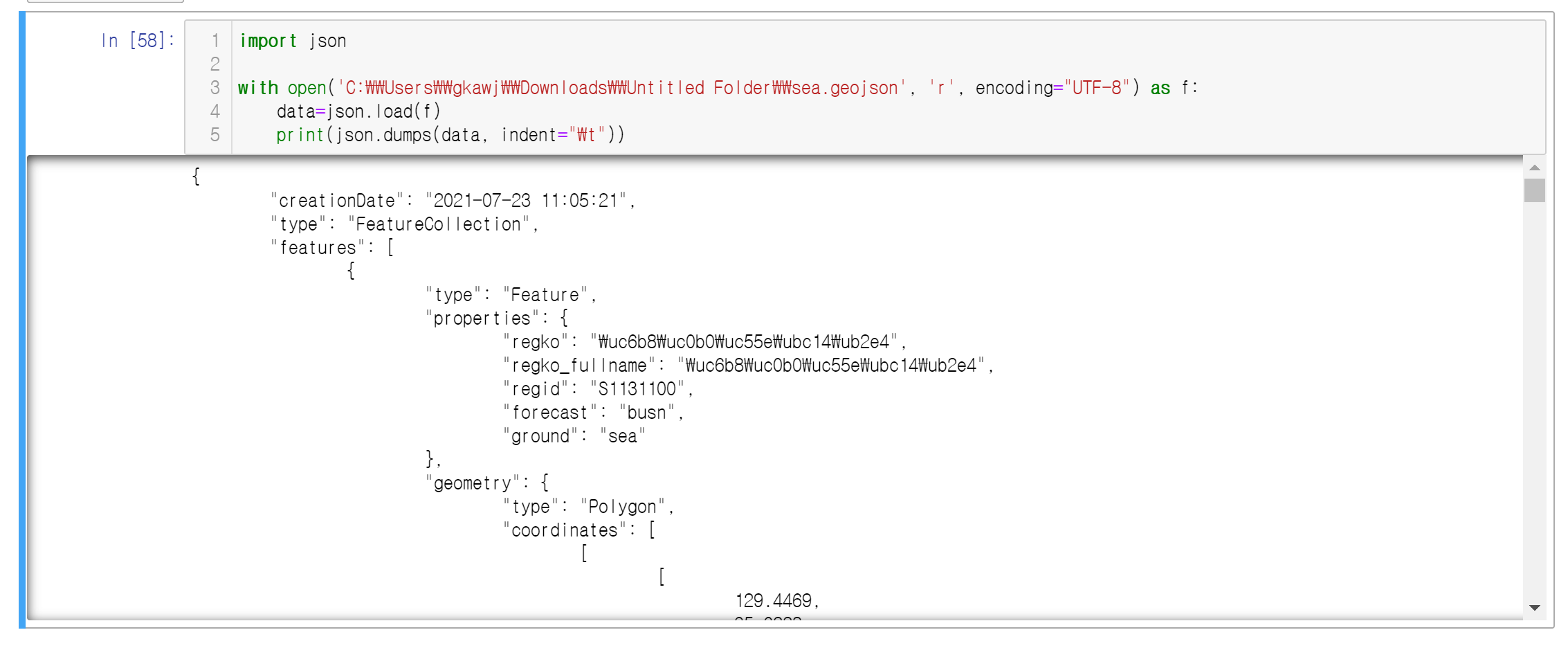
예외가 발생하지는 않았으나, 한글로 표시되어야 할 regko키와 regko_fullname키의 값이 한글이 유니코드로 표출됨을 확인할 수 있다. 이 경우 ensure_ascii속성을 False로 설정하면 해결할 수 있다.
# 수정 전
print(json.dumps(data, indent="\t")) #indent속성을 통해 불러온 json파일의 내용을 적절한 여백으로 표출한다
# 수정 후
print(json.dumps(data, indent="\t", ensure_ascii=False))
https://jsikim1.tistory.com/222
Python json dump 한글 깨짐 해결 방법 (json 파일 쓰기 한글 유니코드 변환 해결 방법)
Python json dump 한글 깨짐 해결 방법 (json 파일 쓰기 한글 유니코드 변환 해결 방법) Python 에서 json.dump() 를 사용하여 json 파일을 생성하려고 할 때, 한글이 깨지는 현상이 나타날 수 있습니다. Python..
jsikim1.tistory.com
2. 필요한 값 변수에 저장하기
본인의 경우 필요한 값을 재사용할 필요가 없어 배열로 값을 저장하지 않은 상태이며 그에 대한 코드는 아래와 같다.
import json
with open('C:\\Users\\gkawj\\Downloads\\Untitled Folder\\sea.geojson', 'r',encoding="UTF-8") as f:
data=json.load(f)
dataLength=len(data['features'])#features의 length
for i in range(dataLength):
regID=data['features'][i]['properties']['regid']
regNAME=data['features'][i]['properties']['regko_fullname']
coordinate=data['features'][i]['geometry']['coordinates']
print(regID)
print(regNAME)
print(coordinate)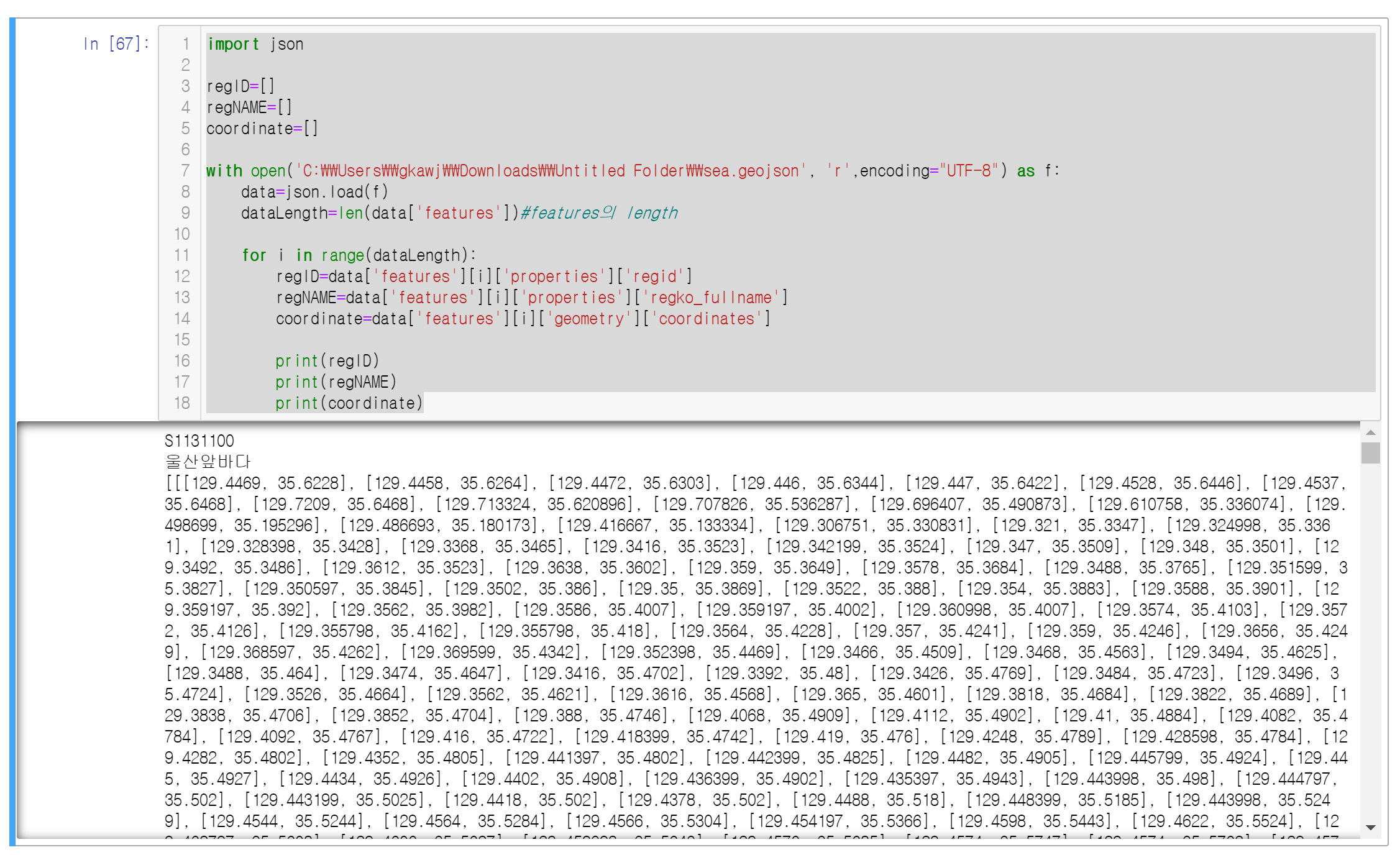
만약 필요한 내용을 배열로 담고싶었다면 아래와 같이 할 수 있겠다.
import json
regID=[]
regNAME=[]
coordinate=[]
with open('C:\\Users\\gkawj\\Downloads\\Untitled Folder\\sea.geojson', 'r',encoding="UTF-8") as f:
data=json.load(f)
dataLength=len(data['features'])#features의 length
for i in range(dataLength):
regID.insert(i, data['features'][i]['properties']['regid'])
regNAME.insert(i, data['features'][i]['properties']['regko_fullname'])
coordinate.insert(i, data['features'][i]['geometry']['coordinates'])
print(regID)
print(regNAME)
print(coordinate)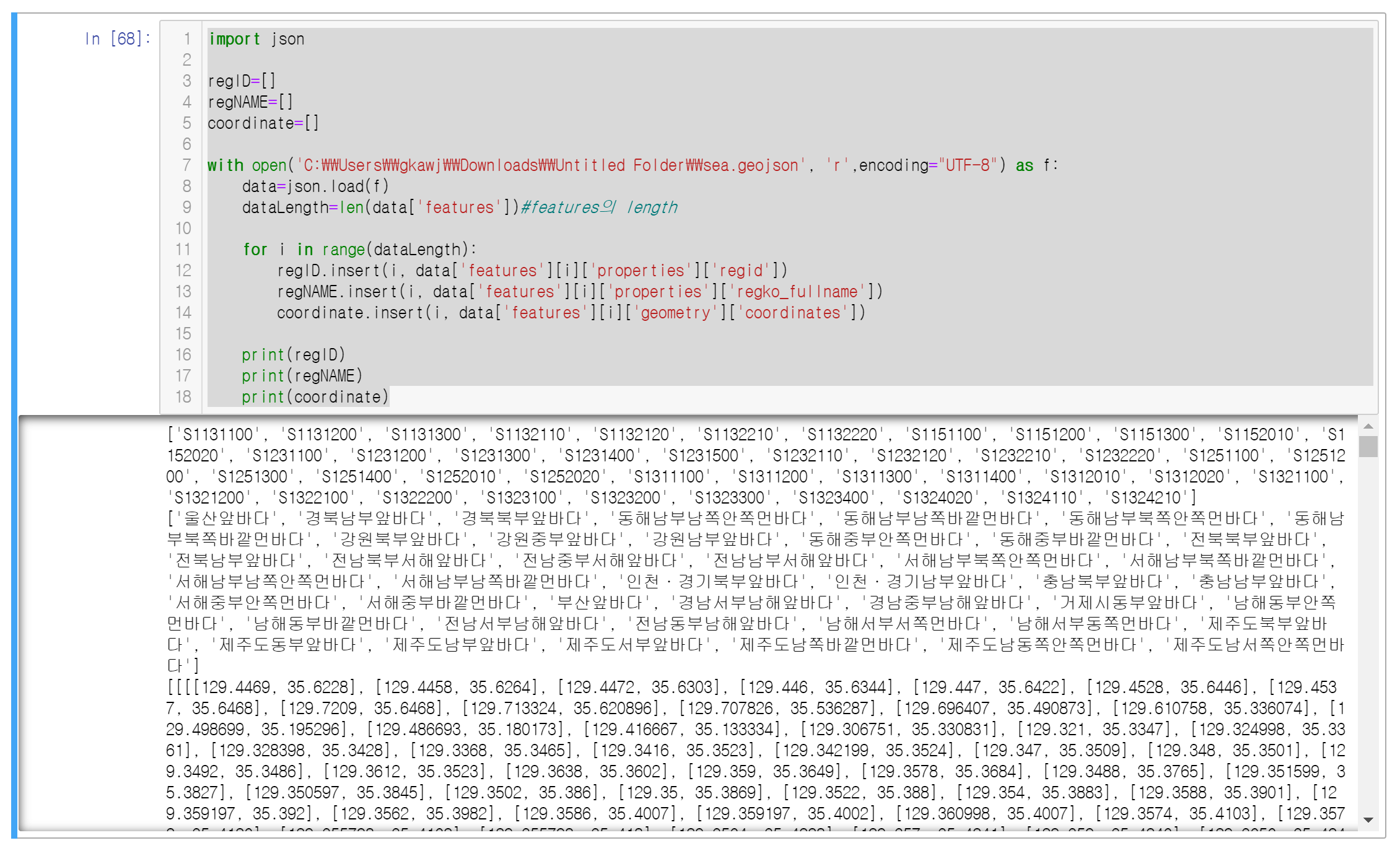
1) TypeError: list indices must be integers or slices, not str
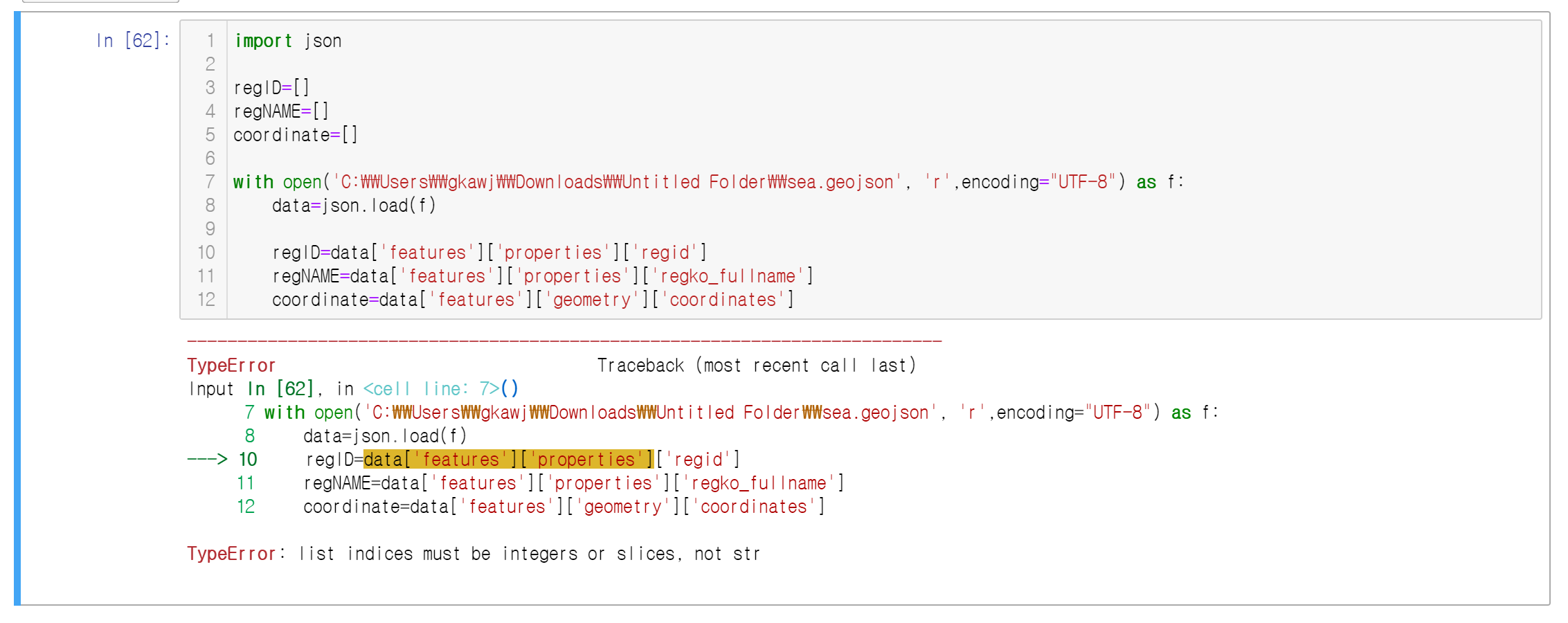
키를 통해 값에 접근하는 것은 맞으나, features의 value로 properties가 존재하기 때문에 features의 특정 인덱스에 존재하는 properties라고 정확히 명시하지 않아 발생한 오류이다.
regID=data['features'][인덱스]['properties']['regid']위와 같은 작성법을 통해 특정 인덱스의 regid를 확인할 수 있게 된다. 본인의 경우에는 모든 인덱스에 대한 정보가 필요했기에 반복문을 통해 모든 정보를 순회하였다.
Python and JSON - TypeError list indices must be integers not str
I am learning to use Python and APIs (specifically, this World Cup API, http://www.kimonolabs.com/worldcup/explorer) The JSON data looks like this: [ { "firstName": "Nicolas Alexis Julio", ...
stackoverflow.com
3. 파일 쓰기
아래의 코드를 통해 정상적으로 파일이 생성된 모습을 확인할 수 있다.
import json
with open('C:\\Users\\gkawj\\Downloads\\Untitled Folder\\sea.geojson', 'r',encoding="UTF-8") as f:
data=json.load(f)
dataLength=len(data['features'])
for i in range(dataLength):
regID=data['features'][i]['properties']['regid']
regNAME=data['features'][i]['properties']['regko_fullname']
coordinate=data['features'][i]['geometry']['coordinates']
#print(regID)
#print(regNAME)
#print(coordinate)
writeData={
"type": "FeatureCollection",
"name": regID,
"features": [{
"type": "Feature",
"properties": {
"regId": regID,
"regFullName": regNAME
},
"geometry": {
"type": "MultiPolygon",
"coordinates": [coordinate]
}
}]
}
with open('./'+regID+'.geojson', 'w', encoding='utf-8') as f:
json.dump(writeData, f, indent="\t", ensure_ascii=False)#indent설정을 통해 여백을 주어 가독성있는 파일이 생성된다
#print(json.dumps(data, indent="\t", ensure_ascii=False)) #출력 완료
1) 인코딩 문제(한글깨짐)
파일 작성을 위한 with문을 작성할때도, 위와 마찬가지로 디코딩 에러를 피하기 위해 encoding속성값을 UTF-8로 명시해주어야하며, 생성된 파일 내에 한글이 유니코드로 표시될 시에는 dump함수를 수행할때 ensure_ascii의 값을 False로 주어야한다. 이에 대한 설명은 목차 1-2와 1-3에 기재된 내용과 일치하기에 자세한 내용은 생략한다.
# 오류 가능성 있는 코드
with open('./'+regID+'.geojson', 'w') as f:
json.dump(writeData, f, indent="\t")
# 오류 없는 코드
with open('./'+regID+'.geojson', 'w', encoding='utf-8') as f:
json.dump(writeData, f, indent="\t", ensure_ascii=False)
'Python' 카테고리의 다른 글
| [아나콘다] 데이터 시각화 (0) | 2022.05.13 |
|---|---|
| [아나콘다] 데이터 분석 및 가공_3 (0) | 2022.05.13 |
| [아나콘다] 데이터 분석 및 가공_2 (0) | 2022.05.11 |
| [아나콘다] 데이터 분석 및 가공 (0) | 2022.05.10 |
| [IDLE] 데이터 분석 및 가공 (0) | 2022.05.10 |


